LM Dictionary vs. finbert vs. T5#
%config InlineBackend.figure_format='retina'
import logging
import warnings
from ekorpkit import eKonf
logging.basicConfig(level=logging.WARNING)
warnings.filterwarnings('ignore')
print(eKonf.__version__)
0.1.33+30.gbd0c674.dirty
Prepare financial_phrasebank dataset#
ds_name = "financial_phrasebank"
cfg = eKonf.compose('dataset/simple=' + ds_name)
cfg.data_dir = '../data/' + ds_name
cfg.io.force.build = True
cfg.io.force.summarize = True
db = eKonf.instantiate(cfg)
apply len_bytes to num_bytes: 100%|██████████| 207/207 [00:21<00:00, 9.68it/s]
apply len_bytes to num_bytes: 100%|██████████| 226/226 [00:04<00:00, 51.35it/s]
apply len_bytes to num_bytes: 100%|██████████| 181/181 [00:00<00:00, 697.31it/s]
ds_cfg = eKonf.compose('dataset')
ds_cfg.name = 'financial_phrasebank'
ds_cfg.path.cache.uri = 'https://github.com/entelecheia/ekorpkit-book/raw/main/assets/data/financial_phrasebank.zip'
ds_cfg.data_dir = ds_cfg.path.cached_path
ds_cfg.verbose = False
ds = eKonf.instantiate(ds_cfg)
print(ds)
Dataset : financial_phrasebank
Instantiating a sentiment analyser class with financial_phrasebank dataset#
model_cfg = eKonf.compose('model/sentiment=lm')
cfg = eKonf.compose(config_group='pipeline')
cfg.verbose = False
cfg.data.dataset = ds_cfg
cfg._pipeline_ = ['predict']
cfg.predict.model = model_cfg
cfg.predict.output_dir = "../data/predict"
cfg.predict.output_file = f'{ds_cfg.name}.parquet'
cfg.num_workers = 1
df = eKonf.instantiate(cfg)
df
{'train': id text labels \
index
0 655 Customers in a wide range of industries use ou... neutral
1 634 The writing and publication of Lemmink+ñinen -... neutral
2 1030 Sullivan said some of the boards `` really inv... neutral
3 317 The six breweries recorded a 5.2 percent growt... positive
4 868 In the second quarter of 2010 , the company 's... positive
... ... ... ...
1440 136 In the fourth quarter of 2009 , Orion 's net p... positive
1441 2170 Profit for the period totalled EUR 1.1 mn , do... negative
1442 344 The diluted loss per share narrowed to EUR 0.2... positive
1443 573 LKAB , headquartered in Lulea , Sweden , is a ... neutral
1444 1768 The EBRD is using its own funds to provide a 2... neutral
subset split num_tokens polarity polarity_label \
index
0 sentences_allagree train 15.0 0.000000 neutral
1 sentences_allagree train 22.0 0.999999 positive
2 sentences_allagree train 24.0 0.000000 neutral
3 sentences_allagree train 27.0 0.000000 neutral
4 sentences_allagree train 29.0 -0.999999 negative
... ... ... ... ... ...
1440 sentences_allagree train 20.0 0.000000 neutral
1441 sentences_allagree train 21.0 0.000000 neutral
1442 sentences_allagree train 13.0 -0.999999 negative
1443 sentences_allagree train 23.0 0.000000 neutral
1444 sentences_allagree train 41.0 0.000000 neutral
uncertainty
index
0 0.000001
1 0.000001
2 0.000001
3 0.000001
4 0.000001
... ...
1440 0.000001
1441 0.000001
1442 0.000001
1443 0.000001
1444 0.000001
[1445 rows x 9 columns],
'test': id text labels \
0 505 Los Angeles-based Pacific Office Properties Tr... neutral
1 783 Investors will continue being interested in th... positive
2 2253 Repeats sees 2008 operating profit down y-y ( ... negative
3 1374 The acquisition was financed with $ 2.56 billi... neutral
4 243 Profit per share was EUR 1.03 , up from EUR 0.... positive
.. ... ... ...
447 605 The commission said the hydrogen peroxide and ... neutral
448 2258 Sales in Finland decreased by 2.0 % , and inte... negative
449 254 The earnings per share for the quarter came in... positive
450 1390 The company can not give up palm oil altogethe... neutral
451 181 Pretax profit rose to EUR 1,019 mn from EUR 1,... positive
subset split num_tokens polarity polarity_label \
0 sentences_allagree test 36.0 0.0 neutral
1 sentences_allagree test 20.0 0.0 neutral
2 sentences_allagree test 16.0 0.0 neutral
3 sentences_allagree test 18.0 0.0 neutral
4 sentences_allagree test 12.0 0.0 neutral
.. ... ... ... ... ...
447 sentences_allagree test 18.0 0.0 neutral
448 sentences_allagree test 30.0 0.0 neutral
449 sentences_allagree test 26.0 0.0 neutral
450 sentences_allagree test 12.0 0.0 neutral
451 sentences_allagree test 17.0 0.0 neutral
uncertainty
0 0.000001
1 0.000001
2 0.000001
3 0.000001
4 0.000001
.. ...
447 0.000001
448 0.000001
449 0.000001
450 0.000001
451 0.000001
[452 rows x 9 columns],
'dev': id text labels \
0 1449 The identity of the buyer is not yet known . neutral
1 165 Operating profit rose to EUR 3.2 mn from EUR 1... positive
2 1334 Previously , Grimaldi held a 46.43 pct stake i... neutral
3 907 A total of $ 78 million will be invested in th... neutral
4 1371 The 19,200-square metre technology center is l... neutral
.. ... ... ...
357 1120 Under a preliminary estimation , the technolog... neutral
358 404 Operating profit improved by 27 % to EUR 579.8... positive
359 1708 Rohwedder Group is an automotive supplies , te... neutral
360 225 In January-September 2007 , the group 's net s... positive
361 1008 Payment of shares shall be effected on subscri... neutral
subset split num_tokens polarity polarity_label \
0 sentences_allagree dev 10.0 0.000000 neutral
1 sentences_allagree dev 18.0 0.000000 neutral
2 sentences_allagree dev 21.0 0.000000 neutral
3 sentences_allagree dev 13.0 0.000000 neutral
4 sentences_allagree dev 15.0 0.000000 neutral
.. ... ... ... ... ...
357 sentences_allagree dev 15.0 0.000000 neutral
358 sentences_allagree dev 17.0 0.999999 positive
359 sentences_allagree dev 22.0 0.000000 neutral
360 sentences_allagree dev 28.0 0.000000 neutral
361 sentences_allagree dev 9.0 0.000000 neutral
uncertainty
0 0.000001
1 0.000001
2 0.000001
3 0.000001
4 0.000001
.. ...
357 0.066668
358 0.000001
359 0.000001
360 0.000001
361 0.000001
[362 rows x 9 columns]}
print(cfg.predict.output_dir)
print(cfg.predict.output_file)
../data/predict
financial_phrasebank.parquet
tmp_df = eKonf.load_data("financial_phrasebank-dev.parquet", cfg.predict.output_dir)
tmp_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 362 entries, 0 to 361
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 362 non-null int64
1 text 362 non-null object
2 labels 362 non-null object
3 subset 362 non-null object
4 split 362 non-null object
5 num_tokens 360 non-null float64
6 polarity 360 non-null float64
7 polarity_label 360 non-null object
8 uncertainty 360 non-null float64
dtypes: float64(3), int64(1), object(5)
memory usage: 25.6+ KB
eval_cfg = eKonf.compose('model/eval=classification')
eval_cfg.columns.actual = 'labels'
eval_cfg.columns.predicted = 'polarity_label'
eval_cfg.labels = ['positive','neutral','negative']
eval_cfg.data_dir = '../data/predict'
eval_cfg.data_file = 'financial_phrasebank-*.parquet'
eval_cfg.output_dir = '../data/eval'
eKonf.instantiate(eval_cfg)
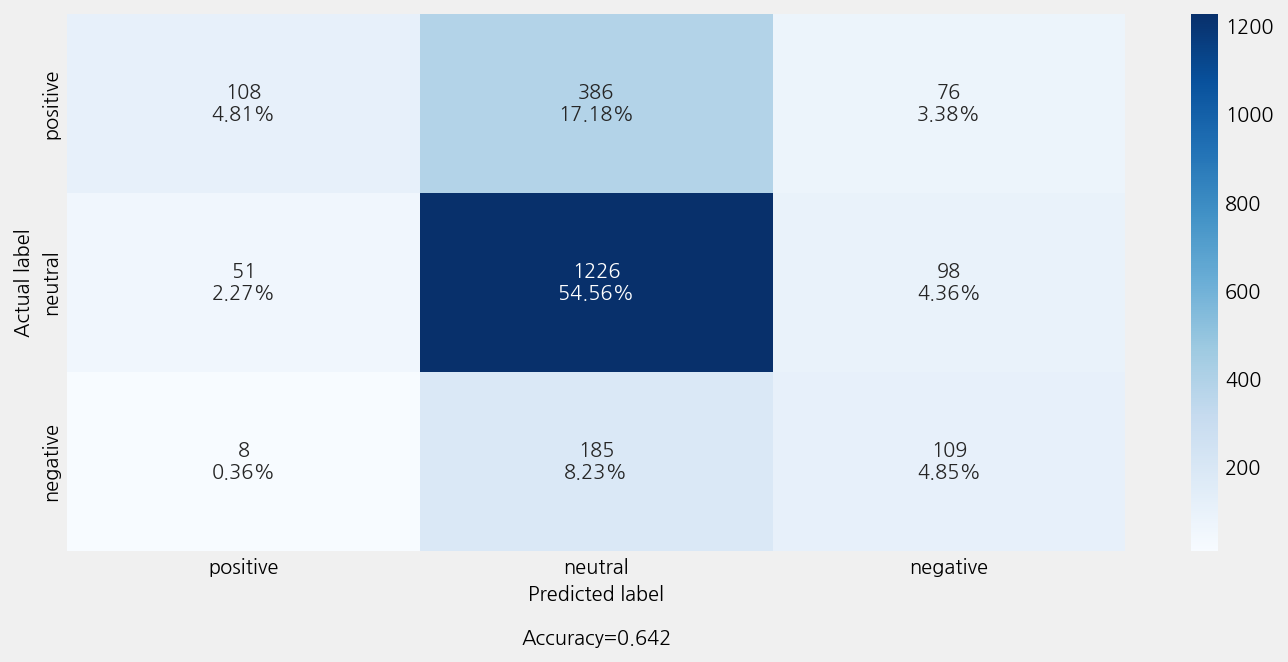
Accuracy: 0.6421895861148198
Precison: 0.6333030880769485
Recall: 0.6421895861148198
F1 Score: 0.5974587783784485
Model Report:
___________________________________________________
precision recall f1-score support
negative 0.39 0.36 0.37 302
neutral 0.68 0.89 0.77 1375
positive 0.65 0.19 0.29 570
accuracy 0.64 2247
macro avg 0.57 0.48 0.48 2247
weighted avg 0.63 0.64 0.60 2247
Instantiating a transformer classficiation model with financial_phrasebank dataset#
overrides=[
'+model/transformer=classification',
'+model/transformer/pretrained=finbert',
]
model_cfg = eKonf.compose('model/transformer=classification', overrides)
model_cfg.dataset = ds_cfg
model_cfg.verbose = False
model_cfg.config.num_train_epochs = 2
model_cfg.config.max_seq_length = 256
model_cfg.config.train_batch_size = 32
model_cfg.config.eval_batch_size = 32
model_cfg.labels = ['positive','neutral','negative']
model_cfg._method_ = ['train']
eKonf.instantiate(model_cfg)
wandb: Currently logged in as: entelecheia. Use `wandb login --relogin` to force relogin
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
Tracking run with wandb version 0.12.18
Run data is saved locally in
/workspace/projects/esgml/outputs/esgml-esgml/finbert/wandb/run-20220620_074520-24c3zvxpFinishing last run (ID:24c3zvxp) before initializing another...
Waiting for W&B process to finish... (success).
Run history:
| Training loss | ▁ |
| acc | ▁█ |
| eval_loss | █▁ |
| global_step | ▁▂█ |
| lr | ▁ |
| mcc | ▁█ |
| train_loss | █▁ |
Run summary:
| Training loss | 0.5406 |
| acc | 0.91436 |
| eval_loss | 0.29525 |
| global_step | 92 |
| lr | 2e-05 |
| mcc | 0.84103 |
| train_loss | 0.17862 |
Synced peach-cosmos-3: https://wandb.ai/entelecheia/esgml-esgml/runs/24c3zvxp
Synced 4 W&B file(s), 0 media file(s), 0 artifact file(s) and 0 other file(s)
Synced 4 W&B file(s), 0 media file(s), 0 artifact file(s) and 0 other file(s)
Find logs at:
/workspace/projects/esgml/outputs/esgml-esgml/finbert/wandb/run-20220620_074520-24c3zvxp/logsSuccessfully finished last run (ID:24c3zvxp). Initializing new run:
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
Tracking run with wandb version 0.12.18
Run data is saved locally in
/workspace/projects/esgml/outputs/esgml-esgml/finbert/wandb/run-20220620_074542-2s94lgmw<ekorpkit.models.transformer.simple.SimpleClassification at 0x7f7987df2820>
overrides=[
'+model/transformer=classification',
'+model/transformer/pretrained=finbert',
]
model_cfg = eKonf.compose('model/transformer=classification', overrides)
model_cfg.dataset = ds_cfg
model_cfg.verbose = False
model_cfg.config.num_train_epochs = 2
model_cfg.config.max_seq_length = 256
model_cfg.config.train_batch_size = 32
model_cfg.config.eval_batch_size = 32
model_cfg.labels = ['positive','neutral','negative']
model_cfg._method_ = ['eval']
eKonf.instantiate(model_cfg)
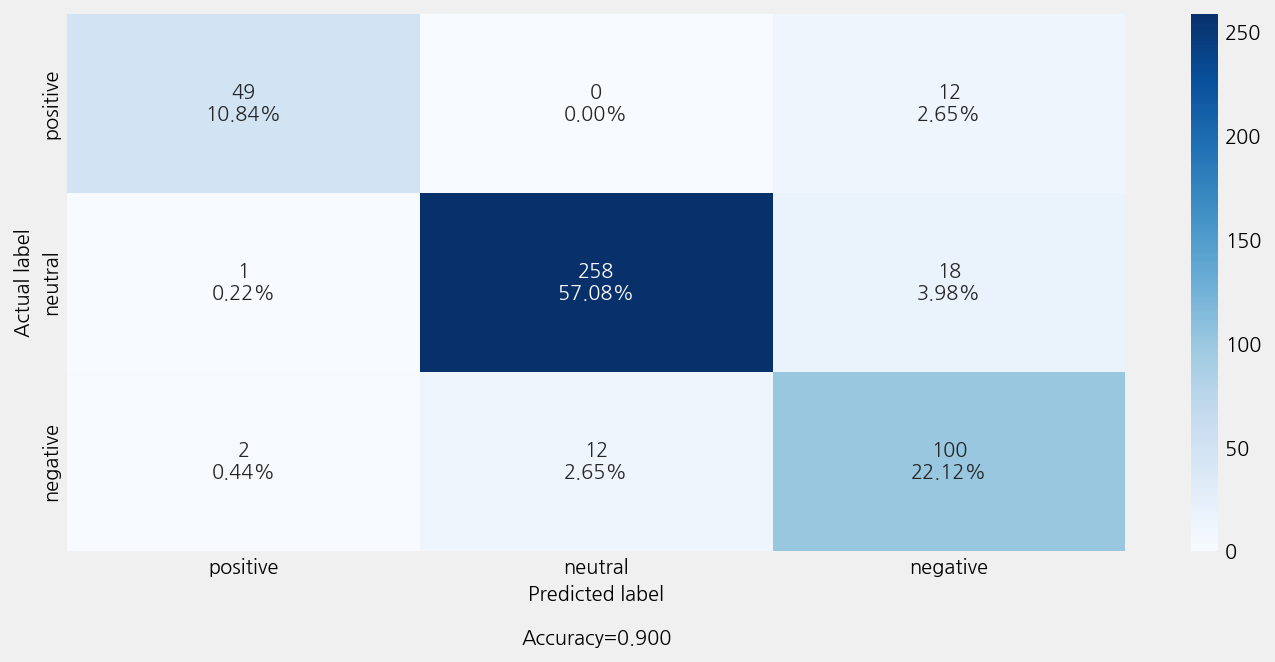
Accuracy: 0.9004424778761062
Precison: 0.9067742606459421
Recall: 0.9004424778761062
F1 Score: 0.90187372379709
Model Report:
___________________________________________________
precision recall f1-score support
negative 0.94 0.80 0.87 61
neutral 0.96 0.93 0.94 277
positive 0.77 0.88 0.82 114
accuracy 0.90 452
macro avg 0.89 0.87 0.88 452
weighted avg 0.91 0.90 0.90 452
<ekorpkit.models.transformer.simple.SimpleClassification at 0x7f78034b6670>
Instantiating a T5 classficiation model with financial_phrasebank dataset#
overrides=[
'+model/transformer=t5_classification_with_simple',
'+model/transformer/pretrained=t5-base',
]
model_cfg = eKonf.compose('model/transformer=t5_classification_with_simple', overrides)
model_cfg.dataset = ds_cfg
model_cfg.verbose = False
model_cfg.config.num_train_epochs = 2
model_cfg.config.max_seq_length = 256
model_cfg.config.train_batch_size = 8
model_cfg.config.eval_batch_size = 8
model_cfg.labels = ['positive','neutral','negative']
model_cfg._method_ = ['train', 'eval']
# model_cfg._method_ = ['eval']
eKonf.instantiate(model_cfg)
Finishing last run (ID:2s94lgmw) before initializing another...
Waiting for W&B process to finish... (success).
Synced sage-fog-4: https://wandb.ai/entelecheia/esgml-esgml/runs/2s94lgmw
Synced 5 W&B file(s), 1 media file(s), 1 artifact file(s) and 0 other file(s)
Synced 5 W&B file(s), 1 media file(s), 1 artifact file(s) and 0 other file(s)
Find logs at:
/workspace/projects/esgml/outputs/esgml-esgml/finbert/wandb/run-20220620_074542-2s94lgmw/logsSuccessfully finished last run (ID:2s94lgmw). Initializing new run:
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
Tracking run with wandb version 0.12.18
Run data is saved locally in
/workspace/projects/esgml/outputs/esgml-esgml/t5-base/wandb/run-20220620_075003-eavxiyyi{'eval_loss': 0.07960319360503681}
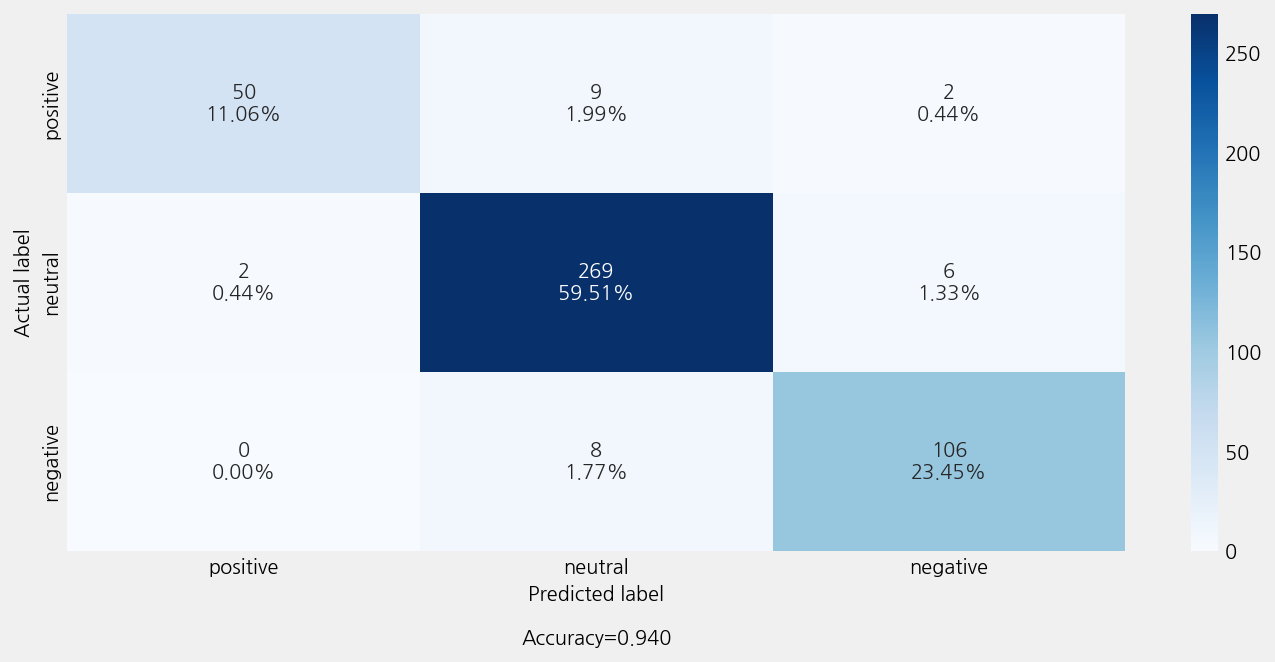
Accuracy: 0.9402654867256637
Precison: 0.9406832105947149
Recall: 0.9402654867256637
F1 Score: 0.9395622196129697
Model Report:
___________________________________________________
precision recall f1-score support
negative 0.96 0.82 0.88 61
neutral 0.94 0.97 0.96 277
positive 0.93 0.93 0.93 114
accuracy 0.94 452
macro avg 0.94 0.91 0.92 452
weighted avg 0.94 0.94 0.94 452
<ekorpkit.models.transformer.simple_t5.SimpleT5 at 0x7f7802a775e0>